
Most Commonly Asked Python Usecases - Part 2 (Pandas Library)
- Jul 12, 2021
- 3 min read
Updated: Jul 19, 2021

Photo by Hitesh Choudhary on Unsplash
Hi All! Hope everyone had wondeful weekend!! This is the part 2 of the most commonly asked python usecases. Last week, we saw in Part 1 python concepts such as lists, list comprehensions, numpy array, sets, dictionaries, etc. This week, we will look into the widely used libraries of python "Pandas DataFrame" and how its most commonly used. Dont Miss the bonus content below.
Most commonly asked Python topics and use cases
Pandas:
1. Accessing the elements in a Pandas Dataframe:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(0,20).reshape(5,4),index=['Row1', 'Row2', 'Row3','Row4', 'Row5'], columns=['Column1','Column2','Column3','Column4'])
df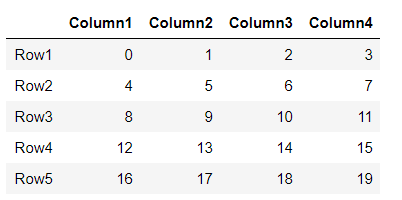
using loc & iloc to access elements in dataframe:
print(df.loc['Row1'])
print(type(df.loc['Row1']))
print(df.iloc[0:2,0:2])
print(type(df.iloc[0:2,0:2]))
As you can see, the data accessed using loc is of series type since we are not getting the data by column indexes whereas data accessed using iloc is of data frame type because we have 2D data i.e. rows and columns specified.
Related concepts: Creating pandas & access elements using loc & iloc:
2. Convert a column to row name index in pandas:
import pandas as pd
Data = {'Fruits': ['apple','pineapple','banana'],
'Cost': [10,10,20],
'Aisle': [1,1,2]}
# Creating a dataframe
df = pd.DataFrame(Data)
# Using set_index()
df = df.set_index('Fruits')
df
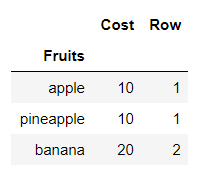
3. Rank the rows:
# import the required packages
import pandas as pd
# Define the dictionary for converting to dataframe
movies = {'Books': ['People skills for Analytical Thinkers', 'Lifes Amazing Secret', 'Spy'],
'Rating': ['5', '5', '3.5']}
df = pd.DataFrame(movies)
# Create a column Rating_Rank which contains
# the rank of each movie based on rating
df['Rating_Rank'] = df['Rating'].rank(ascending = 1)
# Set the index to newly created column, Rating_Rank
df = df.set_index('Rating_Rank')
print(df)
4. Sort values by dataframe column:
# import modules
import pandas as pd
# create dataframe
data = {'Name': ['Alex', 'Sara', 'Niki', 'Daniel', 'Joesph'],
'Maths': [8, 5, 6, 9, 7],
'Science': [7, 9, 5, 4, 7],
'English': [7, 4, 7, 6, 8]}
df = pd.DataFrame(data)
# Sort the dataframe’s rows by Maths
# and then by English, in ascending order
b = df.sort_values(by =['Maths', 'English'])
print("Sort rows by Maths and then by English: \n", b)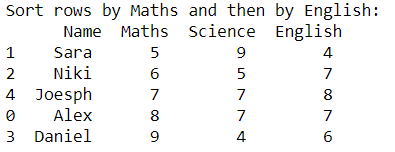
5. Selecting rows with maximum and minimum values in dataframe:
import pandas as pd
print(df[df.Maths == df.Maths.max()])
6. Get all the rows that equals to the column values substring:
df1 = df[df['Name'].str.contains("e")]
df1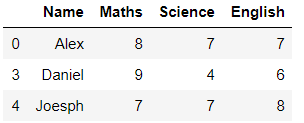
7. Value_counts & unique values in dataframe:
data = {
'item_list':['apple', 'bread', 'orange', 'bread', 'milk','chocolates','apple','books','chocolates']}
df = pd.DataFrame(data)
print(df.item_list.unique())
print(df.item_list.value_counts())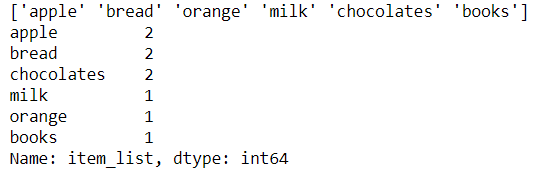
8. Different ways to parse dates:
data = pd.read_csv('order_details.csv')
data.info()
#Parse dates to datetime datatype
print("\n---After parsing the date column---\n")
data1 = pd.read_csv('order_details.csv',parse_dates=['order_date'])
data1.info()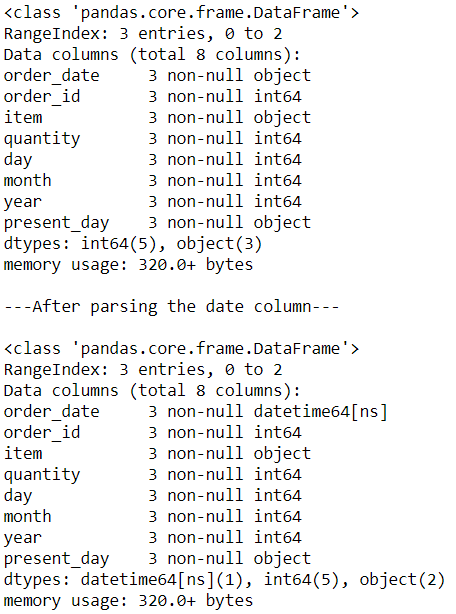
#Parse individuals columns to a date column
print("\n---Parsing individual columns to date---\n")
data2 = pd.read_csv('order_details.csv',
parse_dates=[['year', 'month', 'day']])
data2.info()
print(data2)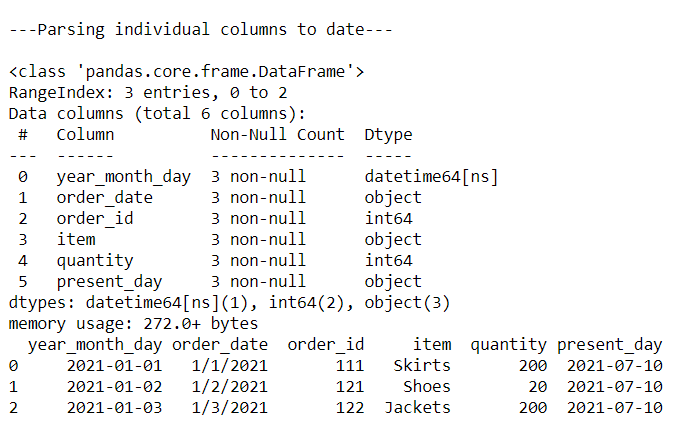
Related concepts: Date parsing using parse_dates function
9. Read Excel using pandas:
In this case, read an unformatted excel file.
import pandas as pd
df = pd.read_excel('shipping.xlsx')
print(df)
df_new = pd.read_excel('shipping.xlsx', header=1, usecols='B:E')
print(df_new)
cols_to_use = ['orderid', 'items','quantity']
df1 = pd.read_excel('shipping.xlsx',
header=1,
usecols=lambda x: x.lower() in cols_to_use)
print(df1)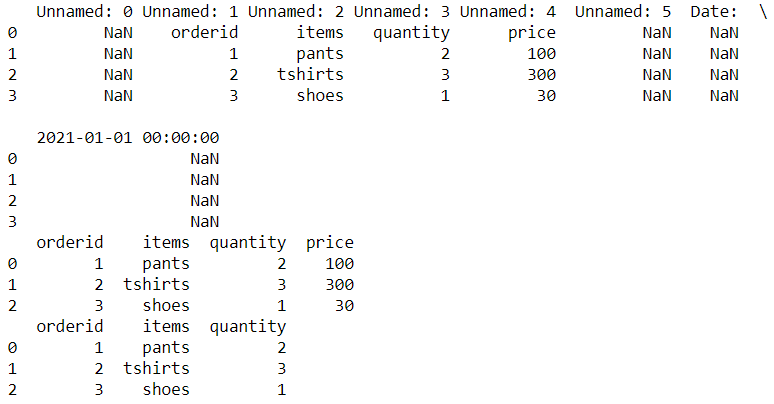
Related concepts: Reading excel file and read data by usecols functions through assign range or column names.
10. Read data tables from html:
If you look at the webpage, you will find several data tables, read_html stores all tables in lists.
import pandas as pd
tables = pd.read_html('https://en.wikipedia.org/wiki/Serena_Williams')
tables[4]
using match parameter to only retrieve table that we need:
table_tournament = pd.read_html('https://en.wikipedia.org/wiki/Serena_Williams',match='Tournament')
table_tournament[0]
Related concepts: Read data from url using read_html() and using match to only read tables that match keyword.
Bonus:
Different ways to create a dataframe: link
How to iterate over rows in pandas dataframe: link
Data Series can either be one row or one column
In python indexing starts from 0 but in R indexing starts from 1
Sometimes we encounter unicode characters while reading data, inorder to escape unicode chracters use encoding='utf-8' while read_csv. If your data is not encoded to utf-8 then try 'latin1'
Usecols can accept Excel ranges such as B:F and read in only those columns. Also, it can take a list of column names
read_html() also takes care of pagination
Best Sources:
Dont Miss the Part 1 of the series
Part 3 will be out next week. If you like this content, please like, share and subscribe!!
Top Viewed articles:



Comments